Dating scams, pet scams, online shopping scams—in today’s digital age, it’s becoming more common to get ensnared by bad actors. A people search tool gives you access to public records and other hard-to-uncover information about a person to help you try and get a better idea of who you’re dealing with.
Thousands of individuals use people search every day to make more informed decisions about who they interact with, both in-person and online. A people search engine combs through available public records, including social, financial and even criminal databases. In a matter of minutes, you can get detailed background and contact information that would be more time-consuming to find otherwise.
The internet has transformed public life. In the past, if you wanted public information about someone, you had to go to the source, such as a courthouse and file a request for paperwork. Today, most public data is available online if you have the right tools to search for and access it.
And in the age of social media, billions of people voluntarily share personal information online on social media platforms, such as Facebook, Instagram, LinkedIn and other networks and forums.
Most popular mobile social networking apps in the United States
September 2019, by Monthly Users in millions
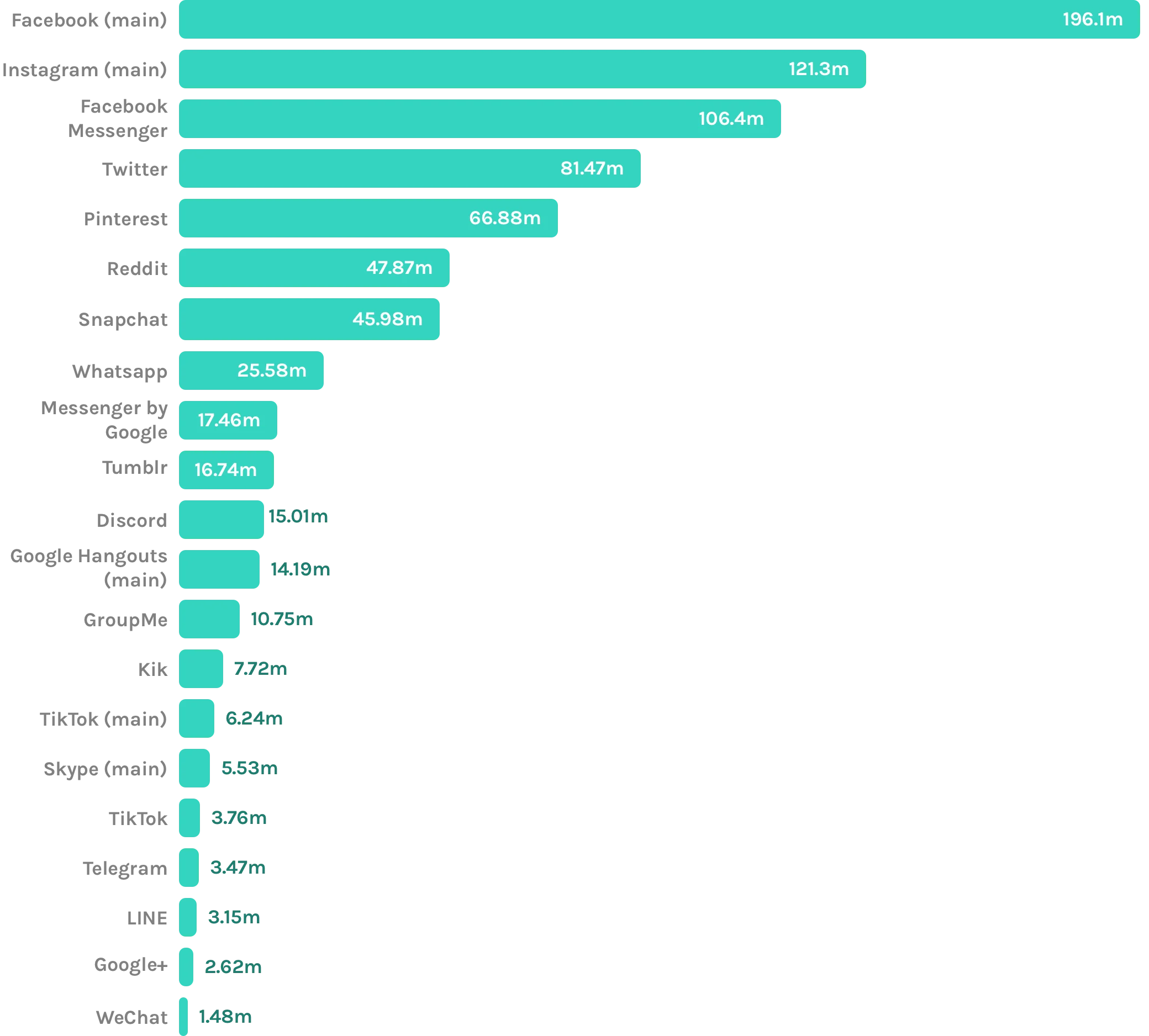
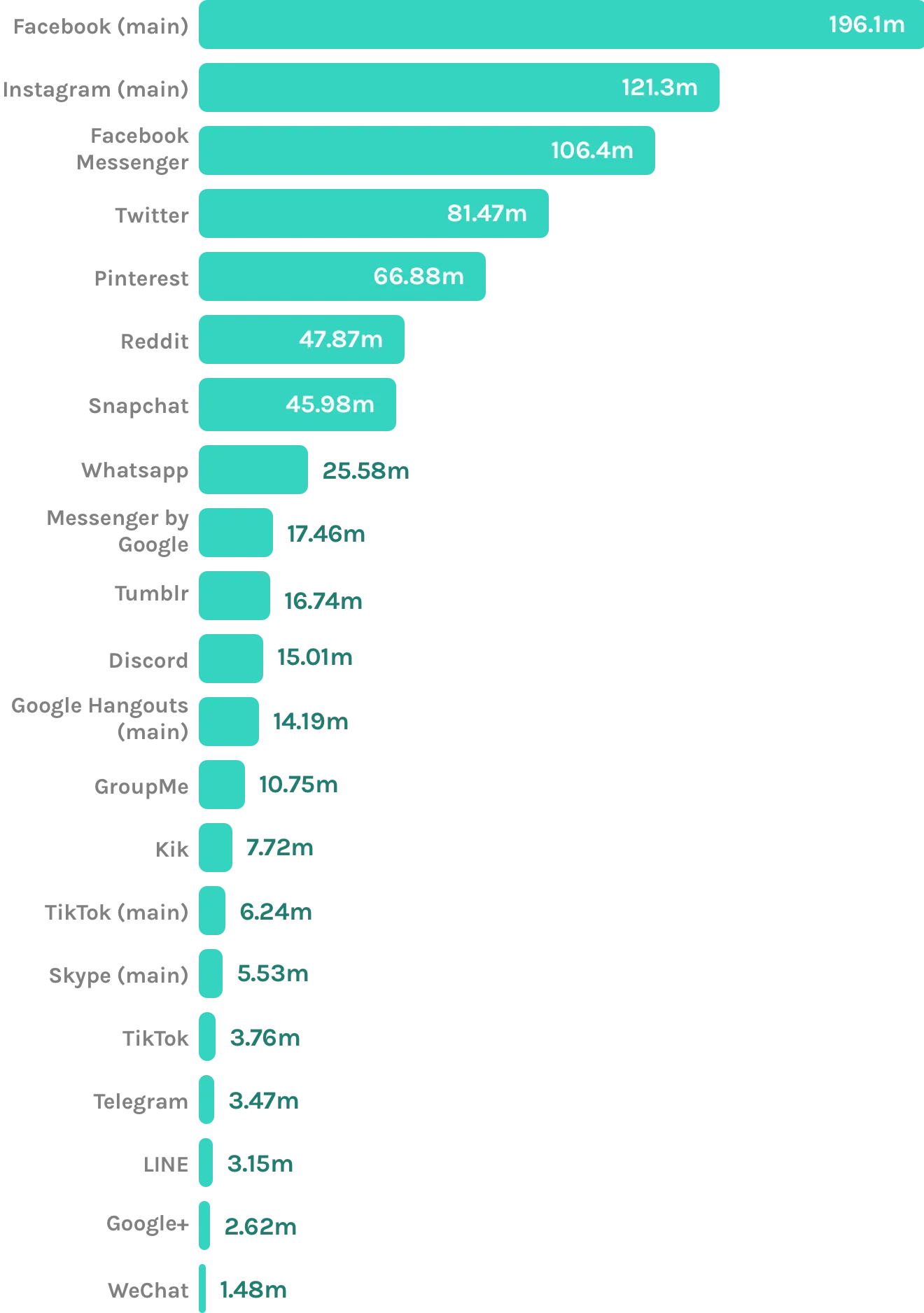
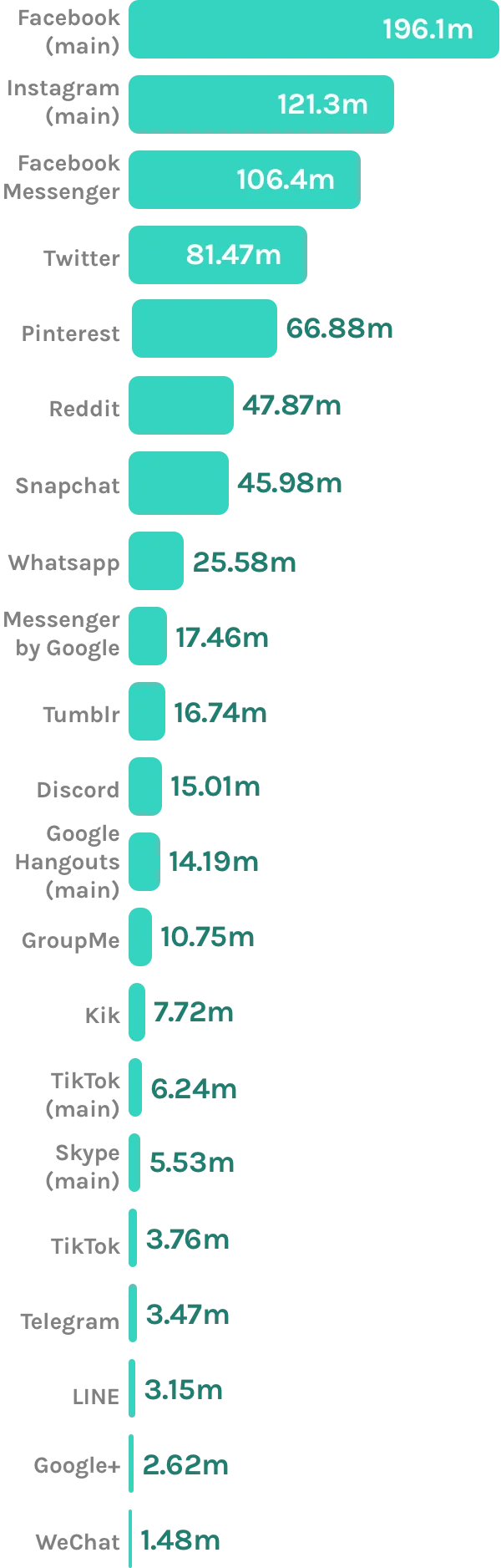
Source: www.statista.com
People Lookup is a sophisticated search tool capable of accessing public records and online databases and cross-referencing and matching the information to provide a more complete view of a person’s identity and background.
A people search may uncover an individual’s full name and aliases, age, current and past addresses and contact information. It may also turn up records such as bankruptcies and other civil and criminal cases. If the person has an online persona, you may be able to see how they present themselves socially and professionally.
It’s more important than ever to protect yourself against online scams; People Search is an excellent tool to try and learn more about someone before interacting with the person on- or offline. Here are some ways People Search can help you:
Most popular online dating apps in the United States
September 2019, by audience size in millions
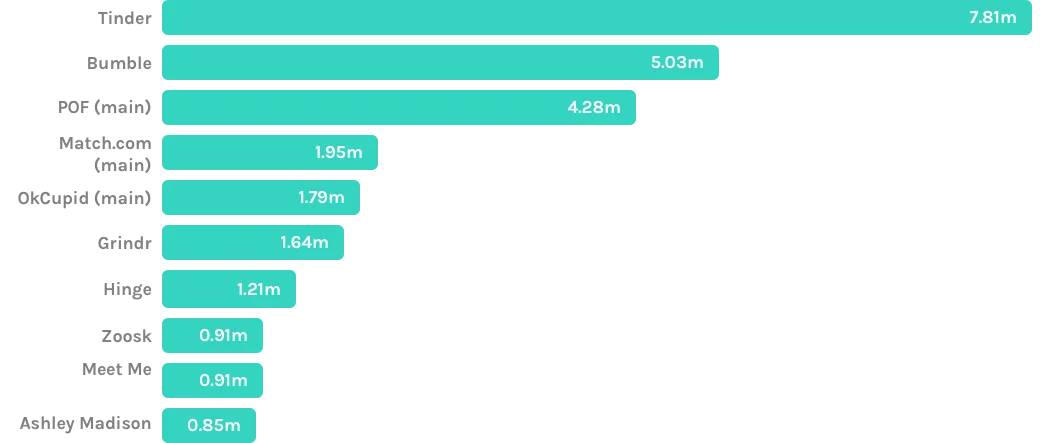
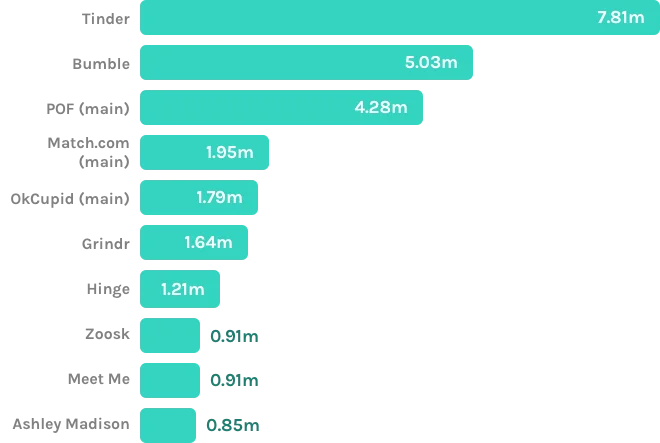

Source: www.statista.com
If you’ve ever Googled yourself, you know that the information you get may be limited. You might find social media matches and White Pages data, but specific information can be hard to locate.
That’s because public search engines don’t have access to the same records databases as a people search engine. They lack the tools to comb public records and connect the dots to give you a more complete picture of the person you’re searching for.
Chances are, if you’re using Yahoo! or Google to find information about someone, you’re looking for specific information to help you make an informed decision about how to interact with them. That kind of data just isn’t available on regular internet search engines. A dedicated people search engine, however, can potentially help uncover the information you need to better protect yourself.
If you have the person’s name, you may have everything you need to start a people search:
Step 1: Enter the person’s first and last name, city and state (if you know it) in the search bar and hit return.
Step 2: The search engine will comb through millions of data points to create a report. There’s a status bar at the top of the screen to track your progress. When it’s ready, you’ll be asked to confirm you’ll use the data appropriately. Create an account to access the full report.
Step 3: Choose how you want to retrieve and view your report.
The Fair Credit Reporting Act was passed in 1970, outlining the type of information public and private organizations can collect about an individual and how that information can be used. It protects people against unauthorized use of their data.
Some information in a people search may be covered by the Fair Credit Reporting Act. This means you can only use the information you obtain in the lawful ways described below.
Although you don’t need a person’s permission to do a search, you do, however, need to follow the law in how you use the data.



Records on the go
With over 7,000,000 downloads so far, PeopleLooker is the go-to choice for mobile public data access. Download now!